Deep Dive: Bagaimana Cara Membangun Neural Network dari Nol
Halo semua! Masih bersama saya di sini. Kali ini, saya ingin membedah lebih dalam proyek lama yang saya buat di GitHub. Proyek ini bukan sekadar copy-paste kode, melainkan usaha untuk memahami setiap baris logika di balik Neural Network.
Inspirasi utamanya datang dari playlist Machine Learning 101 milik Bapak Ridwan Ilyas. Beliau mengajarkan sesuatu yang fundamental: jangan jadi pengguna library yang buta, pahamilah matematikanya.
1. Pergeseran Paradigma: Data + Jawaban = Aturan
Hal pertama yang saya pelajari dari playlist tersebut adalah perbedaan mendasar antara traditional programming dan Machine Learning.
- Pemrograman Tradisional: Kita memasukkan Data dan Aturan (Rule) untuk mendapatkan Jawaban.
- Machine Learning: Kita memberikan Data dan Jawaban, lalu membiarkan mesin mencari Aturan (Model) sendiri.
Inilah yang saya coba pegang ketika melanjutkan studycase dan memahami konteks dari playlist tersebut.
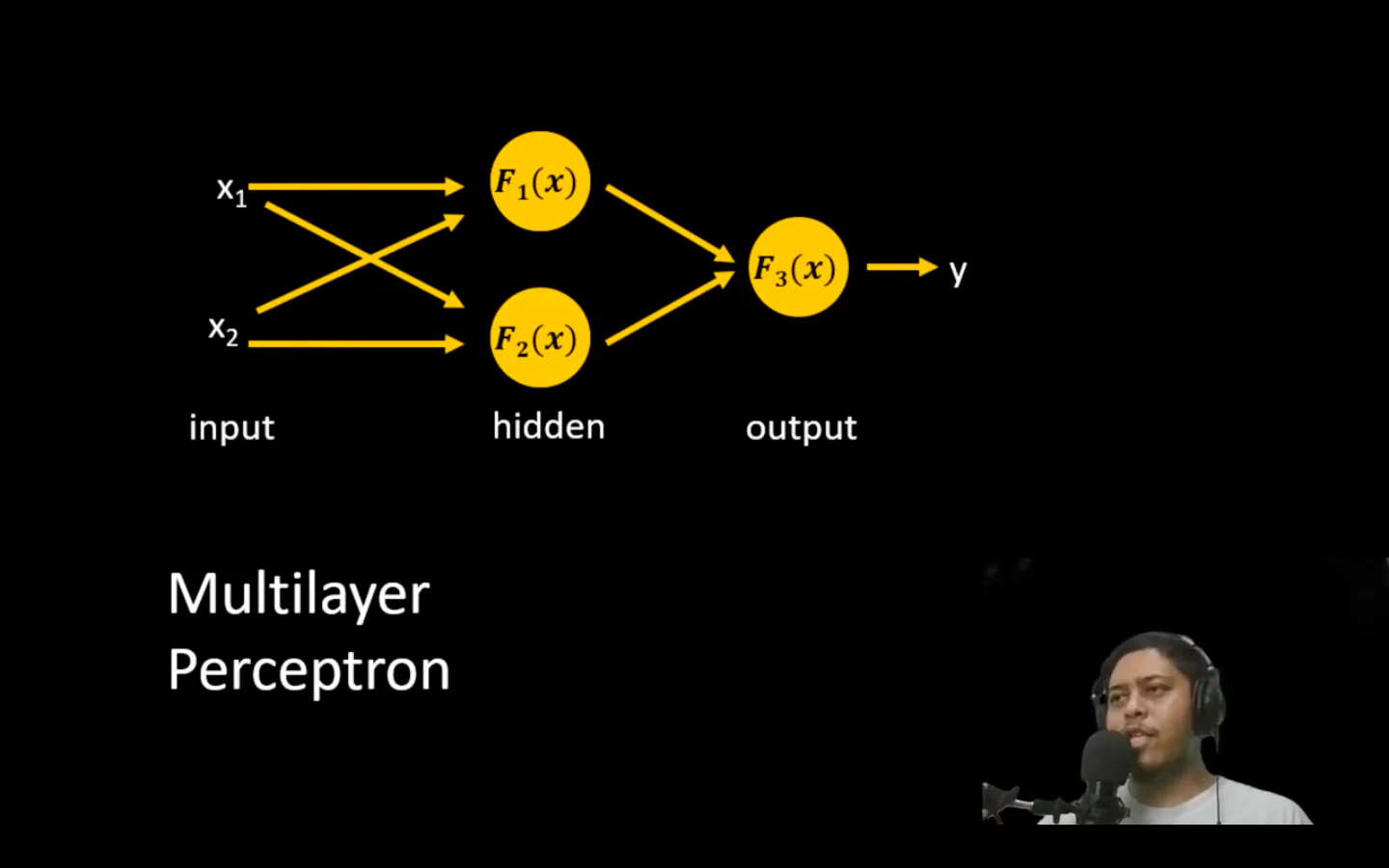
2. Anatomi Jaringan: Lebih dari Sekadar Titik dan Garis
Dalam repo saya, kita merancang struktur utama yang terdiri dari:
- Input Layer: Gerbang awal data.
- Hidden Layer: Di sinilah abstraksi terjadi. Semakin banyak layer, semakin kompleks pola yang bisa dikenali.
- Weights (Bobot) & Bias: Inilah “ingatan” dari model. Saya melakukan inisialisasi bobot secara acak. Mengapa? Jika semua bobot bernilai 0, semua neuron akan menghasilkan output yang sama, dan model tidak akan pernah belajar hal yang unik (symmetry problem).
Setiap neuron dalam kode saya melakukan operasi linear sederhana sebelum masuk ke tahap aktivasi:
$$z = \sum_{i=1}^{n} (w_i \cdot x_i) + b$$

3. Fungsi Aktivasi: Mengatur “Percikan” Neuron
Kenapa kita butuh fungsi aktivasi? Tanpa itu, ribuan layer saraf sekalipun hanya akan menjadi operasi linear raksasa. Saya menggunakan Sigmoid Function dalam studi kasus ini:
$$S(z) = \frac{1}{1 + e^{-z}}$$
Fungsi ini mengubah angka berapapun menjadi rentang 0 hingga 1. Di playlist Pak Ridwan, kita juga belajar fungsi lain seperti Step Function (untuk logika sederhana) atau ReLU. Namun, Sigmoid tetap menjadi pilihan klasik untuk memahami konsep probabilitas klasifikasi.

4. Jantung Model: Backpropagation dan Epochs
Bagian tersulit sekaligus paling menarik adalah proses training. Dalam kode saya, ini bukan sekadar looping, tapi sebuah proses koreksi diri yang presisi:
A. Forward Propagation (Proses Menebak)
Data mengalir dari input ke output. Model memberikan tebakan. Di awal, tebakannya pasti berantakan karena bobotnya masih acak.
B. Menghitung Error (Loss Function)
Saya menggunakan Mean Squared Error (MSE) untuk mengukur seberapa jauh melesetnya tebakan tersebut:
$$MSE = \frac{1}{n} \sum_{i=1}^{n} (y_{pred} - y_{actual})^2$$
C. Backpropagation (Proses Belajar)
Inilah poin penting yang dibahas detail di playlist “Machine Learning 101”. Kita tidak hanya tahu kalau model salah, tapi kita tahu siapa yang harus disalahkan. Melalui teknik kalkulus (turunan), kita menghitung gradient untuk memperbarui bobot:
- Optimizer: Saya menggunakan logika Stochastic Gradient Descent (SGD).
- Learning Rate: Saya menambahkan parameter ini untuk mengatur seberapa drastis model berubah setiap kali ia salah.
- Epochs: Proses ini diulang ratusan hingga ribuan kali (epoch) sampai nilai error mencapai titik terendah.

5. Simulasi Excel ke Python
Salah satu “aha! moment” saya adalah saat melihat simulasi perhitungan manual di Excel dalam playlist tersebut, tepatnya di video ini. Melihat angka-angka bobot berubah di sel Excel membuat saya sadar bahwa AI itu bukan sihir, AI itu statistik yang bekerja keras. Saat saya memindahkan logika tersebut ke Python menggunakan Numpy, semuanya menjadi jauh lebih efisien.
6. Apa yang Saya Pelajari sebagai Engineer?
Setelah menilik ulang kembali proyek neural-network-studycase ini, ada tiga pelajaran berharga:
- Garbage In, Garbage Out: Sebagus apa pun backpropagation kita, kalau datanya kotor (tidak dinormalisasi), model akan bingung.
- Debugging AI itu Beda: Debugging kode biasa itu mencari logic error. Debugging Neural Network itu mencari tahu kenapa model stuck di akurasi 50% (apakah learning rate terlalu besar? atau fungsi aktivasi tidak cocok?).
- Fondasi untuk CNN: Memahami multilayer perceptron dari nol adalah bekal wajib sebelum saya melangkah ke arsitektur yang lebih kompleks seperti Convolutional Neural Networks (CNN)
Secara keseluruhan, playlist tersebut sangat cocok untuk pemula yang ingin mengetahui bagaimana unit terkecil dalam machine learning sebenarnya bekerja.
Penutup & Langkah Selanjutnya
Membangun sesuatu dari nol memberikan kepuasan yang tidak bisa diberikan oleh library instan. Kamu jadi tahu apa yang terjadi saat memanggil fungsi .fit() di masa depan.
Jika teman-teman ingin melihat kotornya tangan saya dengan perhitungan manual ini, silakan mampir ke: 👉 GitHub: akmalsyrf/neural-network-studycase
Jangan lupa beri star atau fork jika kalian ingin bereksperimen juga!
Komentar & Diskusi