Deep Dive: How to Build a Neural Network from Scratch
Hello everyone! Still with me here. This time, I want to dissect an old project of mine on GitHub. This project wasn’t just about copying and pasting code—it was an effort to understand every line of logic behind a Neural Network.
The main inspiration came from the Machine Learning 101 playlist by Mr. Ridwan Ilyas. He taught something fundamental: don’t be a blind library user; understand the math.
1. Paradigm Shift: Data + Answers = Rules
The first thing I learned from that playlist was the fundamental difference between traditional programming and Machine Learning.
- Traditional Programming: We input Data and Rules to get an Answer.
- Machine Learning: We provide Data and Answers, then let the machine find the Rules (Model) itself.
This is the principle I held onto while working through the study case and understanding the context of the playlist.
2. Anatomy of the Network: More Than Just Dots and Lines
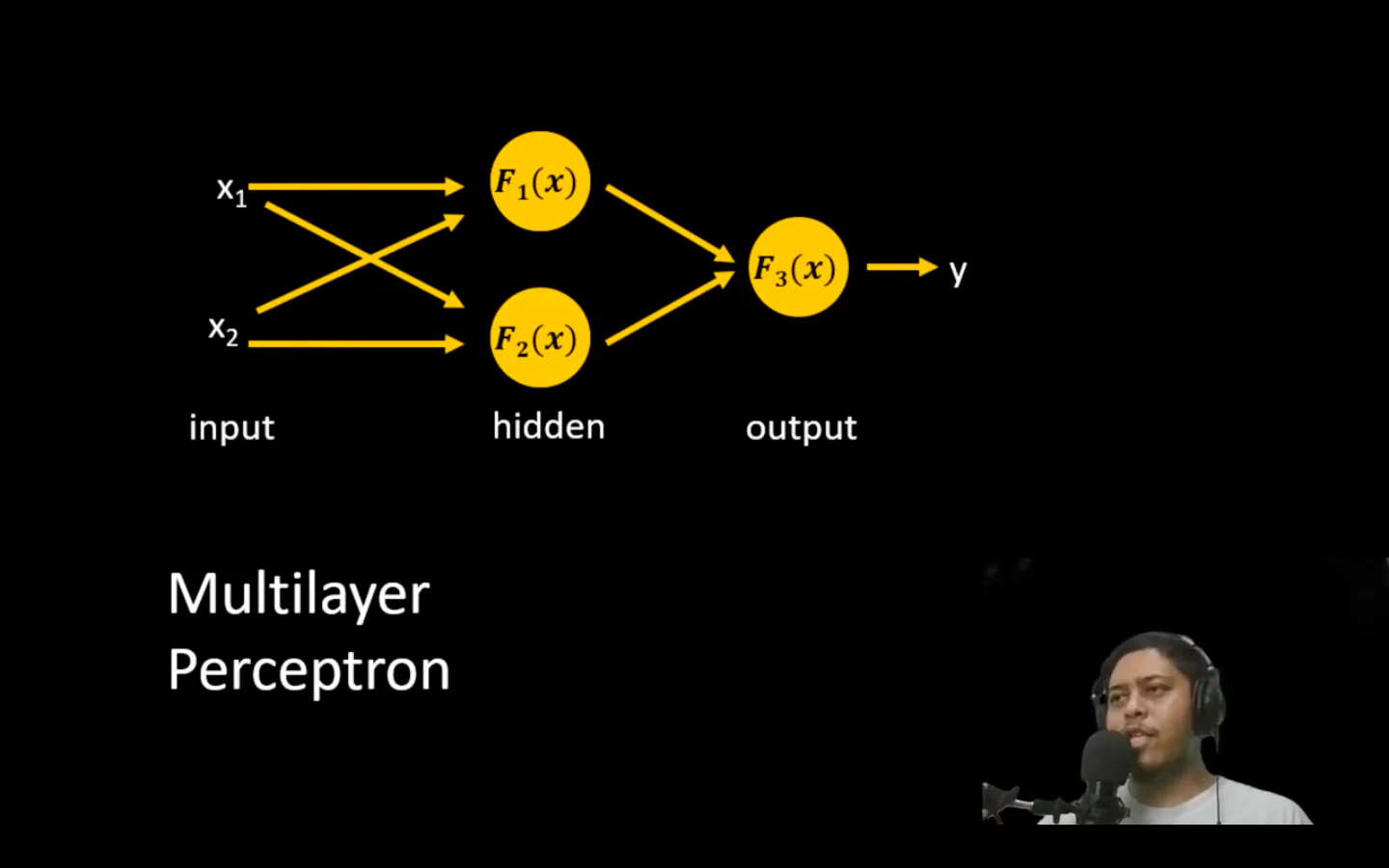
In my repo, we designed a main structure consisting of:
- Input Layer: The initial gateway for data.
- Hidden Layer: This is where abstraction happens. The more layers there are, the more complex the patterns the model can recognize.
- Weights & Bias: This is the “memory” of the model. I initialized the weights randomly. Why? If all weights are 0, every neuron will produce the same output, and the model will never learn unique features (the symmetry problem).
Each neuron in my code performs a simple linear operation before moving to the activation stage:

3. Activation Function: Controlling the Neuron’s “Spark”
Why do we need an activation function? Without it, even thousands of neural layers would just be one giant linear operation. I used the Sigmoid Function in this study case:
This function maps any number into a range of 0 to 1. In Pak Ridwan’s playlist, we also learned about other functions like the Step Function (for simple logic) or ReLU. However, Sigmoid remains a classic choice for understanding classification probability.

4. The Heart of the Model: Backpropagation and Epochs
The hardest yet most interesting part is the training process. In my code, this isn’t just a loop; it’s a precise self-correction process:
A. Forward Propagation (The Guessing Process)
Data flows from input to output. The model makes a guess. Initially, the guess is bound to be messy because the weights are still random.
B. Calculating Error (Loss Function)
I used Mean Squared Error (MSE) to measure how far off the guess was:
C. Backpropagation (The Learning Process)
This is the crucial point discussed in detail in the “Machine Learning 101” playlist. We don’t just know that the model is wrong; we know who to blame. Through calculus (derivatives), we calculate the gradient to update the weights:
- Optimizer: I used Stochastic Gradient Descent (SGD) logic.
- Learning Rate: I added this parameter to control how drastically the model changes every time it makes an error.
- Epochs: This process is repeated hundreds or thousands of times (epochs) until the error value reaches its lowest point.

5. Simulating from Excel to Python
One of my “aha! moments” was seeing the manual calculation simulation in Excel from the playlist, specifically in this video. Seeing the weight values change in Excel cells made me realize that AI isn’t magic; AI is statistics working hard. When I moved that logic to Python using Numpy, everything became much more efficient.
6. What Did I Learn as an Engineer?
After looking back at this neural-network-studycase project, there are three valuable lessons:
- Garbage In, Garbage Out: No matter how good our backpropagation is, if the data is dirty (not normalized), the model will be confused.
- Debugging AI is Different: Normal debugging is about finding logic errors. Debugging a Neural Network is about finding out why the model is stuck at 50% accuracy (is the learning rate too high? is the activation function unsuitable?).
- Foundation for CNN: Understanding multilayer perceptrons from scratch is a mandatory prerequisite before moving on to more complex architectures like Convolutional Neural Networks (CNN).
Overall, the playlist is perfect for beginners who want to know how the smallest units of machine learning actually function.
Conclusion & Next Steps
Building something from scratch provides a satisfaction that instant libraries cannot give. You get to know exactly what happens when you call the .fit() function in the future.
If you want to see my hands get dirty with these manual calculations, feel free to stop by: 👉 GitHub: akmalsyrf/neural-network-studycase
Don’t forget to leave a star or fork it if you want to experiment yourself!
Comments & Discussion